Introduction
From python 3.2 and forward an excellent module called concurrent.futures is available. It makes it very easy to do multi-threading or multi-processing:
The concurrent.futures module provides a high-level interface for asynchronously executing callables. The asynchronous execution can be performed with threads, using ThreadPoolExecutor, or separate processes, using ProcessPoolExecutor.
Parallel execution of pandas dataframe with a progress bar
In a concrete problem I recently faced I had a large dataframe and a heavy function to execute on each row using a subset of columns from the dataframe. Usually, I would have used the apply method to work through the rows, but apply only uses 1 core of the available cores.
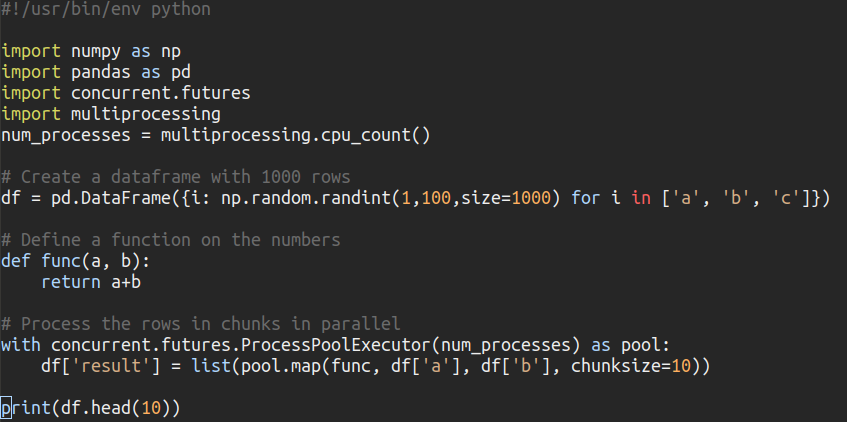
In the made up example below, I am using concurrent.futures to process the dataframe on all available cores. Of course this doesn’t make sense for simple operations as summation below, but for heavy calculations it can make a large impact to use all the available computing power. Also note that I am sending the rows in chunks of 10 to the executor – this reduces the overhead of returning the results.
import tqdm import numpy as np import pandas as pd import concurrent.futures import multiprocessing num_processes = multiprocessing.cpu_count() # Create a dataframe with 1000 rows df = pd.DataFrame({i: np.random.randint(1,100,size=1000) for i in ['a', 'b', 'c']}) # Define a function on the numbers def func(a, b): return a+b # Process the rows in chunks in parallel with concurrent.futures.ProcessPoolExecutor(num_processes) as pool: #df['result'] = list(pool.map(func, df['a'], df['b'], chunksize=10)) # Without a progressbar df['result'] = list(tqdm.tqdm(pool.map(func, df['a'], df['b'], chunksize=10), total=df.shape[0])) # With a progressbar
The results are in the same order as the original dataframe and the result of the calculation saved in a separate column.
>>>print(df.head(10)) a b c result 0 44 7 72 51 1 49 77 30 126 2 74 69 38 143 3 70 25 69 95 4 44 98 20 142 5 10 89 85 99 6 85 47 92 132 7 58 19 16 77 8 46 47 52 93 9 65 87 79 152

You don’t need to import multiprocessing or acquire the processor count yourself at all. The Executor does that for you if you dont give it a set number.
Good point. Thanks 🙂